对象序列化的目标是将对象保存到磁盘中,或允许在网络中直接传输对象。对象序列化机制允许把内存中的java对象转换成平台无关的二进制流,从而允许把这种二进制流持久的保存在磁盘上,通过网络将这种二进制流传输到另一个网络节点。
序列化机制使对象可以脱离程序的运行而独立存在。对象的序列化(Serialize)是指将一个java对象写入IO流中,对象的反序列化(Deserialize)则是从IO流中恢复java对象。
java对象实现序列化必须让该类实现如下两个接口之一:
- Serializable
- Externalizable
当一个对象实现了Serializable接口时,通过一个写输出流就可以把对象存在磁盘上。示例如下:
ObjectOutputStream oos=new ObjectOutputStream(new FileOutputStream("object.txt"));
Person per=new Person("ericson",25);
oos.writeObject(per);而反序列化则是相反的过程,通过一个输入流来恢复对象。如下所示:
ObjectInputStream ois=new ObjectInputStream(new FileInputStream("object.txt"));
Person per=(Person)ois.readObject();当一个可序列化类有多个父类(直接父类或间接父类)时,这些父类要么有无参构造器,要么也是可序列化的,否则抛出InvalidClassException异常;如果父类不可序列化,只有带有无参构造器,则父类中定义的Field值不会被序列化到二进制流中。
序列化引用对象,先来看下面代码:
Person per=new Person("ericson",25);
Teacher t1=new Teacher("xiong",per);
Teacher t2=new Teacher("yue",per);从上面代码可以看出:如果序列化上面三个对象,会对per对象序列化三次,当再反序列化时,就会生成三个Person对象,不符合引用关系。因此java采用了特殊的序列化算法:
- 所有保存到磁盘的序列化对象都有一个序列化编号
- 当程序试图序列化一个对象时,会先检查该对象有没有被序列化过,只有该对象没有被序列化过,才会将该对象转换字节序列输出
- 如果某个对象序列化过了,程序将只是直接输出一个序列化编号,而不是重新序列化该对象
在序列化对象代码后改变对象的值不会改变序列化的内容,反序列化还是那个对象。
当不需要序列化某个Field时,可以在该Field前面使用transient关键字,指定java序列化无需理会该Field。transient只能用于修饰Field。
自定义序列化,需要自己重写writeObject方法和readObject方法。还可以重写writeReplace方法把对象转成其他对象,如下所示:
private Object writeReplace() throws ObjectStreamException{
ArrayList<Object> list=new ArrayList<Object>();
list.add(name);
list.add(age);
return list;
}上面的代码就把Person对象转变为ArrayList对象,java在序列化时总会先调用writeReplace方法,所以就变成了对ArrayList的序列化;反序列化的结果也是ArrayList的对象。与writeReplace对应的方法是readResolve方法,该方法在readObject方法之后执行,该方法返回值会替换掉原来的反序列化对象。readResolve在序列化单例类、枚举类时尤其有用。因为反序列化不需要通过构造函数来创建对象,所以对于单例类,需要重写readResolve来屏蔽错误,该方法要为private,不然在继承关系上容易出错。
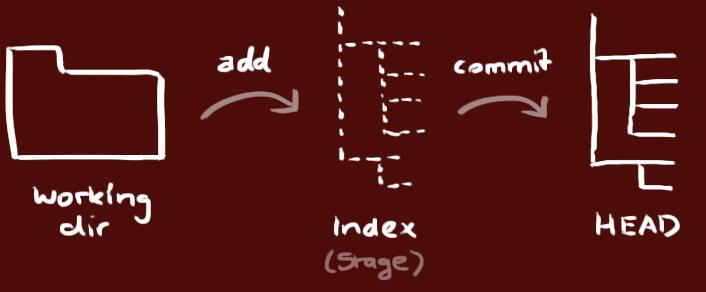 5.添加与提交,你可以计划改动(把它们添加到缓存区),使用如下命令:
5.添加与提交,你可以计划改动(把它们添加到缓存区),使用如下命令: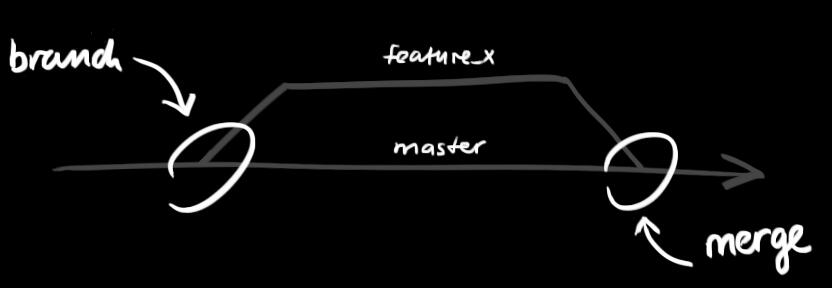 创建一个叫做“feature_x”的分支,并切换过去:
创建一个叫做“feature_x”的分支,并切换过去: