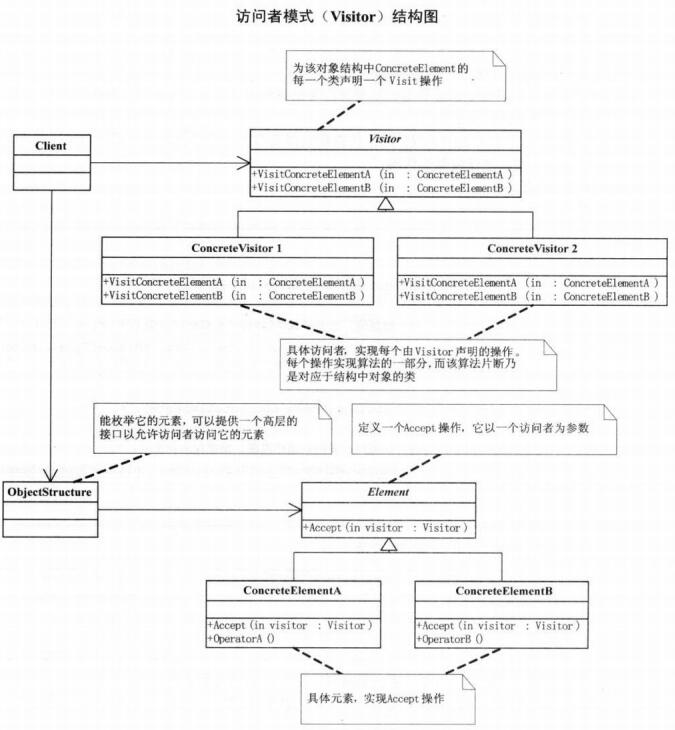
访问者模式,表示一个作用于某对象结构中的各元素的操作,它使你可以在不改变各元素的类的前提下定义作用于这些元素的新元素。访问者模式结构图如下所示:
 访问者模式的目的是要把处理从数据结构分离出来,访问者模式的优点是增加新的操作很容易,因为增加新的操作就意味着增加一个新的访问者。访问者模式将有关的行为集中到一个访问者对象中。访问者模式的缺点其实也就是使增加新的数据结构变得困难。
访问者模式的目的是要把处理从数据结构分离出来,访问者模式的优点是增加新的操作很容易,因为增加新的操作就意味着增加一个新的访问者。访问者模式将有关的行为集中到一个访问者对象中。访问者模式的缺点其实也就是使增加新的数据结构变得困难。
Visitor类,为该对象结构中ConcreteElement的每一个类声明一个Visit操作。
abstract class Visitor{
public abstract void VisitConcreteElementA(ConcreteElementA concreteElementA);
public abstract void VisitConcreteElementB(ConcreteElementB concreteElementB);
}
ConcreteVisitor1和ConcreteVisitor2类,具体访问者,实现每个由Visitor声明的操作。每个操作实现算法的一部分,而该算法片断乃是对应于结构中对象的类。
class ConcreteVisitor1 extends Visitor{
public void VisitConcreteElementA(ConcreteElementA concreteElementA){
System.out.println("A访问");
}
public void VisitConcreteElementB(ConcreteElementB concreteElementB){
System.out.println("B访问");
}
}
class ConcreteVisitor2 extends Visitor{
//同上
}
Element类,定义一个Accept操作,它以一个访问者为参数:
abstract class Element{
public abstract void Accept(Visitor visitor);
}
ConcreteElementA和ConcreteElementB类,具体元素,实现Accept操作:
class ConcreteElementA extends Element{
public void Accept(Visitor visitor){
visitor.VisitConcreteElementA(this);
}
public void OperationA(){}
}
class ConcreteElementB extends Element{
public void Accept(Visitor visitor){
visitor.VisitConcreteElementB(this);
}
}
ObjectStructure类,能枚举它的元素,可以提供一个高层接口以允许访问者访问它的元素。
class ObjectStructure{
private List<Element> elements=new ArrayList<Element>();
private void Attach(Element element){
elements.add(element);
}
private void Detach(Element element){
elements.remove(element);
}
public void Accept(Visitor visitor){
for(Element e:elements){
e.Accept(visitor);
}
}
}
客户端代码:
static void main(String[] args){
ObjectStructure o=new ObjectStructure();
o.Attach(new ConcreteElementA());
o.Attach(new ConcreteElementB());
ConcreteVisitor1 v1=new ConcreteVisitor1();
ConcreteVisitor2 v2=new ConcreteVisitor2();
o.Accept(v1);
o.Accept(v2);
}
访问者模式优点:
- 符合单一职责原则:凡是适用访问者模式的场景中,元素类中需要封装在访问者中的操作必定是与元素类本身关系不大且是易变的操作,适用访问者模式一方面符合单一职责原则,另一方面,因为被封装的操作通常来说都是易变的,所以当发生变化时,就可以在不改变元素类本身的前提下,实现对变化部分的扩展
- 扩展性良好:元素类可以通过接受不同的访问者实现对不同操作的扩展
访问者模式适用场景:
假如一个对象中存在着一些与本对象不相干(或者关系较弱)的操作,为了避免这些操作污染这个对象,则可以使用访问者模式来把这些操作封装到访问者去。
假如一组对象中,存在着相似的操作,为了避免出现大量重复的代码,也可以将这些重复的操作封装到访问者中去。
但是,访问者模式并不是那么完美,它也有着致命的缺陷:增加新的元素类比较困难。通过访问者模式代码可以看到,在访问者类中,每一个元素类都有它对应的处理方法,也就是说,每增加一个元素类都需要修改访问者类(也包括访问者类的子类或者实现类),修改起来相当麻烦。也就是说,在元素类数目不确定的情况下,应该慎用访问者模式。所以访问者模式比较适用于对已有功能的重构,比如说,一个项目的基本功能已经确定下来,元素类的数据已经基本确定下来不会变了,会变的只有这些元素内的相关操作,这时候,我们可以使用访问者模式对原有的代码进行重构一遍,这样一来,就可以在不修改各个元素类的情况下,对原有功能进行修改。

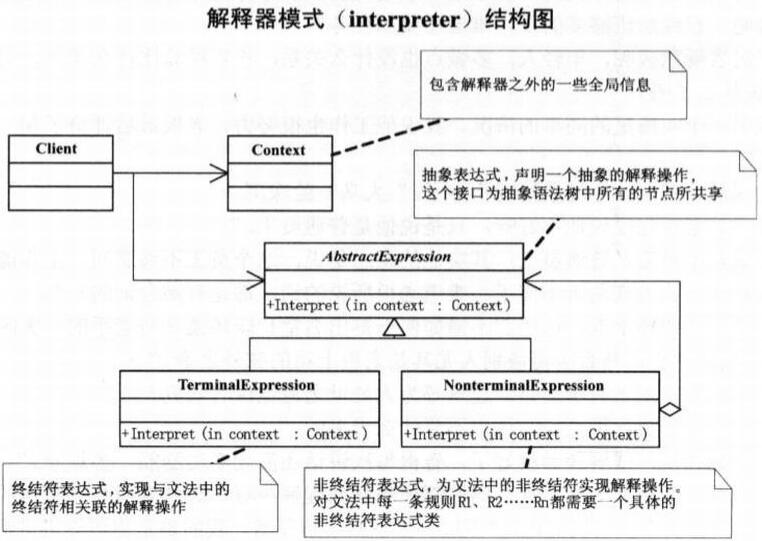 AbstractExpression(抽象表达式),声明一个抽象的解释操作,这个接口为抽象语法树中所有的节点所共享。
AbstractExpression(抽象表达式),声明一个抽象的解释操作,这个接口为抽象语法树中所有的节点所共享。