Java类加载器除了根类加载器之外,其他的都是用java语言编写的。当运行某个java程序时,将会启动一个java虚拟机进程,该程序的所有线程都位于该java虚拟机中。两个JVM之间不能共享数据。
当程序主动使用某个类时,如果该类还未被加载到内存中,则系统会通知加载、连接、初始化3个步骤来对该类进行初始化。类加载指的是将类的class文件读入内存,并为之创建一个java.lang.Class对象。当类被加载之后,系统会为之生成一个对应的Class对象,接着将会进入连接阶段,连接阶段负责把类的二进制数据合并到JAR中。分为以下三个阶段:
- 验证:验证阶段用于检验被加载的类是否有正确的内部结构,并和其他类协调一致
- 准备:类准备阶段则负责为类的静态Field分配内存,并设置默认初始值
- 解析:将类的二进制数据中的符号引用替换成直接引用
在类的初始化阶段,虚拟机负责对类进行初始化,主要就是对静态Field进行初始化。类加载器负责将.class文件加载到内存中,并为之生成对应的java.lang.Class对象。当JVM启动时,会形成3个类加载器组成的初始类加载器层次结构:
- Bootstrap ClassLoader:根类加载器
- Extension ClassLoader:扩展类加载器
- System ClassLoader:系统类加载器
Bootstrap ClassLoader被称为引导类加载器,它负责加载Java核心类。
URL[] urls=sum.misc.Launcher.getBootstrapClassPath().getURLs();
for(int i=0;i<urls.length;i++){
System.out.println(urls[i].toExternalForm());
}
Externsion ClassLoader被称为扩展类加载器,它负责加载JRE的扩展目录中JAR包的类。System ClassLoader被称为系统类加载器,它负责在JVM启动时加载来自java命令的-classpath选项、java.class.path系统属性或CLASSPATH环境变量所指定的JAR包和类路径。
JVM类加载器机制主要有3种:
- 全盘负责:当一个类加载器负责加载某个Class时,该Class所依赖和引用的其他Class也将由该类加载器负责载入,除非显式使用另外一个类加载器来载入
- 父类委托:则是让parent类加载器试图加载该Class,只有在父类加载器无法加载该类时才尝试从自己的类路径中加载该类
- 缓存机制:保证所有加载过的Class都会被缓存,当程序中需要使用某个Class时,类加载器先从缓存区中搜索该Class,只有当缓存区中不存在该Class对象系统才会读取该类对应的二进制数据。
可以通过扩展ClassLoader类来自定义自己的类加载器。ClassLoader有两个关键方法:loadClass(String name,boolean resolve)和findClass(String name)。在ClassLoader里还有一个核心方法:defineClass(String name,byte[] b,int len),该方法负责将指定类的字节码文件读入字节数组b内,并把它转换为Class对象,该字节码文件可以源于文件、网络等。
Java程序中许多对象在运行时都会出现两种类型:编译时类型和运行时类型。例如Person p=new Student();编译时类型为Person,运行时类型为Student。当编译时和运行时完全知道类型的具体信息,在这种情况下,我们可以直接先使用instanceof运算符进行判断,再利用强制类型转换;党编译时根本无法预知该对象和类可能属于哪些类,程序只能依靠运行时的信息来发现该对象和类的真实信息,这就必须使用反射。
Java程序中获得Class对象通常有如下3钟方式:
- 使用Class类的forName(String clazzName)静态方法,该字符串参数的值是某个类的全限定类名
- 调用某个类的class属性来获取该类对应的Class对象,Person.class
- 调用某个对象的getClass方法,该方法将会返回该对象所属类对应的Class对象
Class对象可以获得该类里的方法、构造器、Field,这3个类都位于java.lang.reflect包下,并实现了java.lang.reflect.Member接口。可以通过Class的newInstance方法或者先创建构造器然后通过构造器来实例化对象。Java类可以通过Class类来反射调用java类中的方法。
在java的java.lang.reflect包下提供了一个Proxy类和一个InvocationHandler接口,通过使用这个类和接口可以生成JDK动态代理类或动态代理对象。Proxy提供了用于创建动态代理类和代理对象的静态方法,它也是所有动态代理类的父类。如果在程序中为一个或多个接口动态的生成实现类,就可以使用Proxy来创建动态代理类;如果需要为一个或多个接口动态的创建实例,也可以使用Proxy来创建动态代理实例。Proxy主要包含两个方法:getProxyClass和newProxyInstance方法。InvocationHandler中封装了需要调用的方法。代码示例如下:
InvocationHandler handler=new MyInvocationHandler();
Foo f=(Foo)Proxy.newProxyInstance(Foo.class.getClassLoader(),new Class[]{Foo.class},handler);
动态代理在代码复用中应用很广泛,在AOP(面向切面编程)中也有广泛的使用。

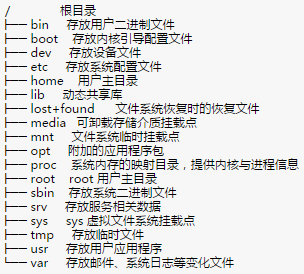 文件分为文件名和数据两部分,这在linux上被分成两个部分:用户数据与元数据。用户数据,即文件数据块,数据块是记录文件真实内容的地方;而元数据则是文件的附加属性,比如文件大小、创建时间等信息。元数据中的inode索引节点号才是文件的唯一标识,而不是文件名。
文件分为文件名和数据两部分,这在linux上被分成两个部分:用户数据与元数据。用户数据,即文件数据块,数据块是记录文件真实内容的地方;而元数据则是文件的附加属性,比如文件大小、创建时间等信息。元数据中的inode索引节点号才是文件的唯一标识,而不是文件名。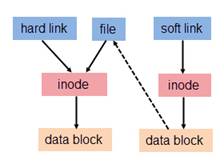
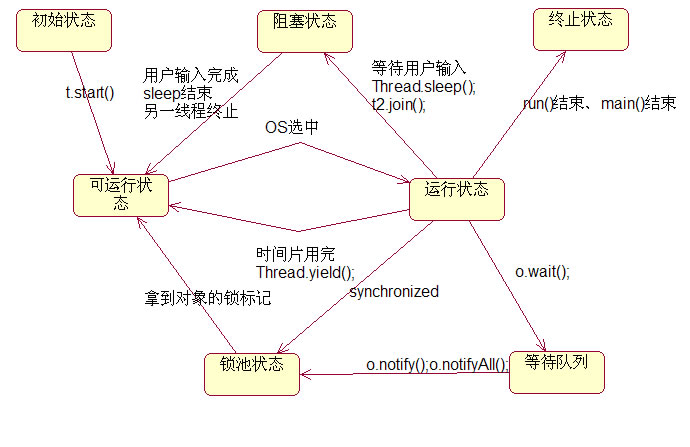 线程控制,Thread提供了让一个线程等待另一个线程完成的方法——join方法。
线程控制,Thread提供了让一个线程等待另一个线程完成的方法——join方法。