Java集合类是一个特别有用的工具类,可以用于存储数量不等的多个对象,并可实现常用的数据结构。
Java集合大致可以分为:Set、List、Map三种体系:
- Set:代表无序、不可重复的集合
- List:代表有序、可重合的集合
- Map:代表具有映射关系的集合
Java集合类主要由两个接口派生而来:Collection和Map,Collection和Map是java集合框架的根接口。Collection接口的继承树如下图所示:
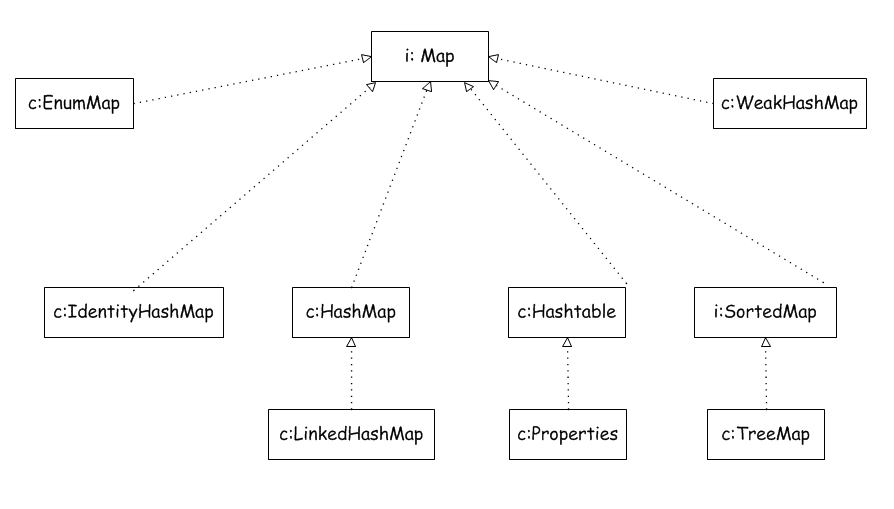
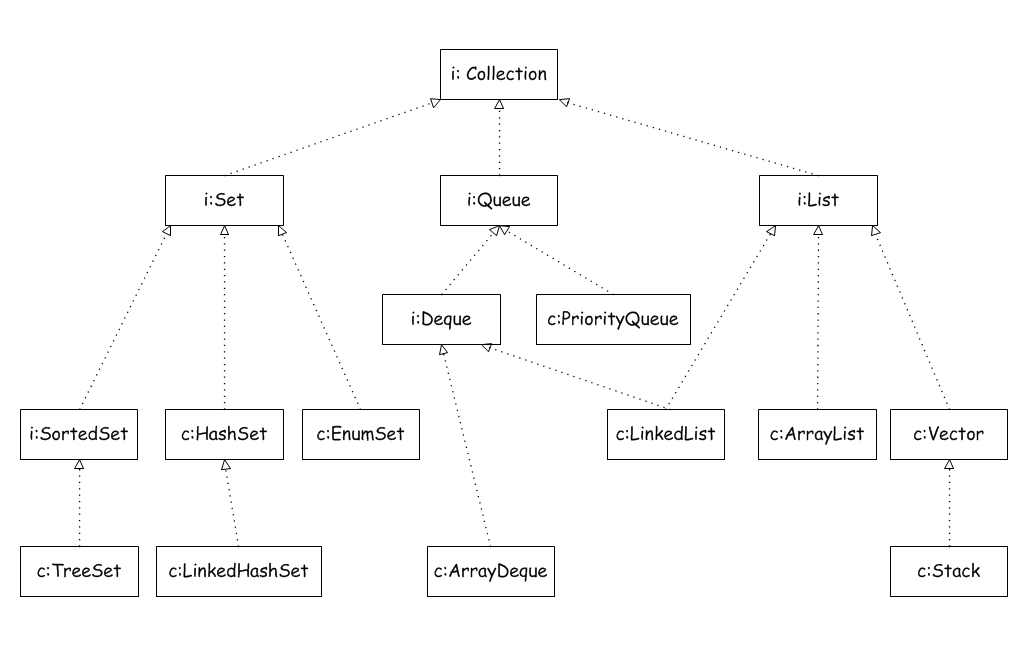 Map接口继承树如下图所示:
Map接口继承树如下图所示:
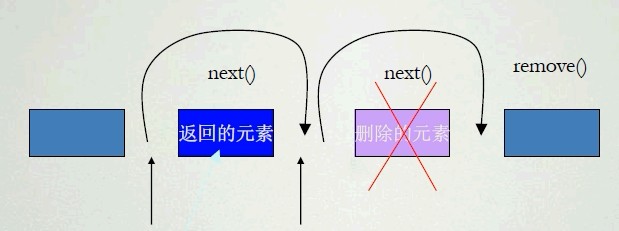
 使用Iterator接口可以遍历集合元素,Iterator本身并不提供盛装对象的能力。当使用Iterator对集合里的元素进行迭代时,Iterator并不是把集合本身传递给迭代变量,而是把集合元素的值传给迭代变量,所以修改迭代变量的值对集合元素本身没有任何影响,但可以删除。
使用Iterator接口可以遍历集合元素,Iterator本身并不提供盛装对象的能力。当使用Iterator对集合里的元素进行迭代时,Iterator并不是把集合本身传递给迭代变量,而是把集合元素的值传给迭代变量,所以修改迭代变量的值对集合元素本身没有任何影响,但可以删除。
[Java Code]
public void iterator(){
Collection books=new ArrayList();
books.add("a");
books.add("b");
books.add("c");
Iterator it=books.iterator();
while(it.hasNext()){
String book=(String)it.next();
book="d";
}
System.out.println(books.toString());
}
输出a,b,c
Iterator是fail-fast机制,一旦在迭代过程中检测到该集合已经被修改过,程序立即引发ConcurrentModificationException异常。Iterator方法的工作原理如下图所示:
Set集合:判断两个对象相同不是用==运算符,而是用equals方法。因此可以修改equals方法来添加相同的元素。
HashSet类:不是同步的,允许null值,HashSet底层实际上是一个HashMap,把<key,value>值封装成一个Map.Entry类,通过Entry类中的key来比较添加的值。HashSet判断两个对象相等的标准是通过equals方法比较相等,并且hashCode方法返回一样的值。当hashCode相同,当equals不同,元素会以链式存储,影响性能。如果修改一个HashSet中的值可能会出现混乱,因为hashCode可能会根据对象的值计算,当改掉该值时,该对象依然存储在原来的hashCode上,但是再次访问它计算hashCode就不是原来的位置了。
LinkedHashSet类:维护元素的插入顺序,因此性能略低于HashSet,但在迭代访问Set里的全部元素时将有很好的性能,因为它以链表来维护内部顺序。该类底层实现是LinkedHashMap类,维护了一个双重链接列表。此链接列表定义了迭代顺序,该类不是同步的。
TreeSet类:是SortedSet接口的实现类,可以确保集合元素处于排序状态。TreeSet是通过比较元素大小来排序,而不是插入顺序,所以要求元素直接必须要是可比较的,如果把一个对象添加到TreeSet中,则该对象的类必须实现Comparable接口,否则程序会抛出异常。TreeSet使用两种排序方法:自然排序和定制排序。
- 自然排序:调用元素的compareTo方法,按元素的升序排序。编程时要尽量确保equals方法和compareTo方法保持一致性。如果TreeSet中包含了可变对象,当可变对象的Field被修改时,TreeSet在处理这些对象时将会非常复杂,而且容易出错。
- 定制排序:通过Comparator接口来重写compareTo方法。
TreeSet类是线程非安全的,源码中是用TreeMap来实现的,而TreeMap采用红黑树的结构来存储数据,是一种自平衡的排序二叉树,TreeSet把<key,value>值封装成Entry类来表示红黑树的一个节点。
EnumSet类:EnumSet类是一个专门为枚举类设计的集合类。EnumSet的集合元素必须是指定枚举类型的枚举值,该枚举类型在创建EnumSet时显示或隐式指定。不允许加入null值。
可以通过Collection工具类的synchronizedSortedSet方法来包装Set集合的同步性。
SortedSet s=Collections.synchronizedSortedSet(new TreeSet(…));
List集合代表一个元素有序、可重复的集合,集合中每个元素都有其对应的顺序索引。List接口还提供了listIterator方法,该方法返回一个ListIterator对象,ListIterator接口继承Iterator接口,还专门提供了一个前向迭代的功能,而且还可以通过add方法向List集合中添加元素(Iterator只能删除元素)。
ArrayList和Vector都是基于数组实现的List,底层的数据结构是数组,所以ArrayList和Vector类封装了一个动态的、允许再分配的Object[]数组。两个类都通过initialCapacity参数来设置该数组的长度,当向其中添加元素超出该数组长度时,它们的initialCapacity会自动增加。ArrayList是线程不安全的,而Vector是线程安全的。所以Vector的性能要比ArrayList的性能低。Vector还有个子类Stack,也是线程安全的,模仿了栈的操作。
Queue用于模拟队列这种数据结构,FIFO。Deque代表一个双端队列,可以同时从两端来添加、删除元素,所以可以当成栈来使用。PriorityQueue保存队列元素的顺序并不是按加入队列的顺序,而是按照队列元素大小进行重新排序。
Deque接口提供了一个实现类ArrayDeque,是基于数组实现的双端队列,底层也是一个Object[]数组来保存元素,如果超出容量,则会重新分配一个Object[]数组来存储集合元素。因为Stack是线程安全的,所以性能较ArrayDeque和LinkedList较差,所以栈结构推荐使用ArrayDeque和LinkedList。
LinkedList类实现了Deque接口,所以可以当成栈,它的底层实现方式是链表,因此随机访问集合元素时性能较差,但在插入和删除方面性能非常出色。对于所有内部基于数组实现的集合,使用随机访问的性能比使用Iterator迭代访问的性能要好,因为随机访问数组会被映射成对数组元素的访问。

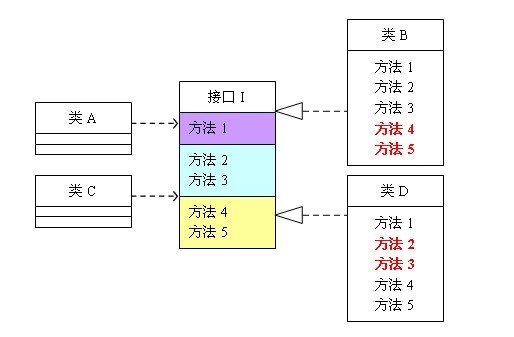 隔离后的实现如下图所示:
隔离后的实现如下图所示:
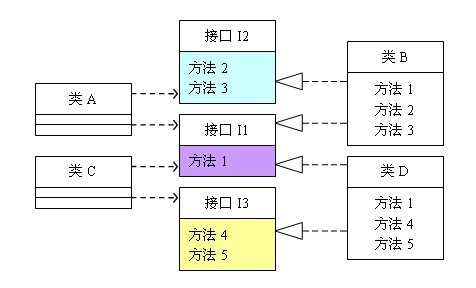 接口隔离的含义是:建立单一接口,不要建立庞大臃肿的接口,尽量细化接口,接口中的方法尽量少。也就是说,我们要为各个类建立专用的接口,而不要试图去建立一个很庞大的接口供所有依赖它的类去调用。单一职责原则注重的是职责的分离,而接口隔离注重的是接口依赖的隔离。
接口隔离的含义是:建立单一接口,不要建立庞大臃肿的接口,尽量细化接口,接口中的方法尽量少。也就是说,我们要为各个类建立专用的接口,而不要试图去建立一个很庞大的接口供所有依赖它的类去调用。单一职责原则注重的是职责的分离,而接口隔离注重的是接口依赖的隔离。